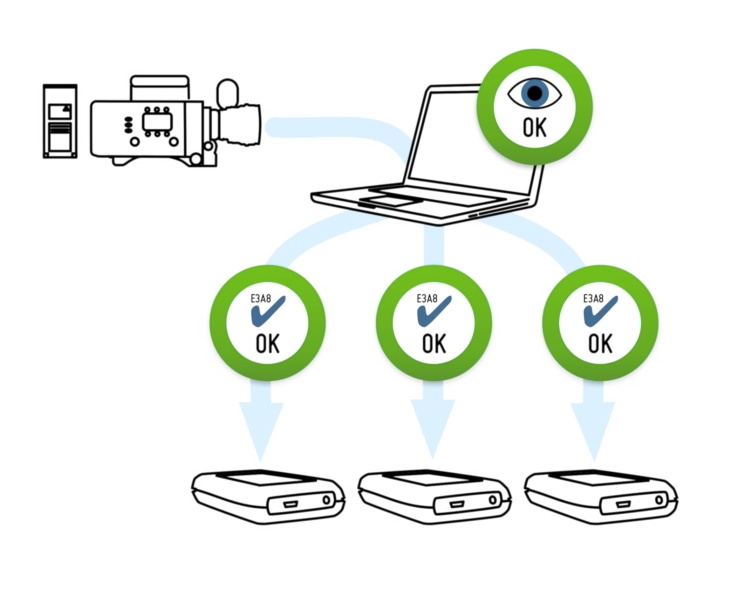
figure 1: checksum verification
Silverstack offers multiple verification methods to compare byte by byte the source file with all of its backup copies. The verification process ensures that no file has been corrupted during the copy process. If the verification process result is positive, Silverstack will create an .mhl file in the main folder of each backup destination. This .mhl file is the seal of file integrity of all copied folders that should go always together with its files, as it will let the user to manually verify each copy of the files to ensure their completeness and consistency.

figure 2: .mhl file placement
Hashing algorithms explained
Hashing algorithms are functions that take a certain amount of data (i.e. a file) and calculate a unique, reproducible, fixed-length “hash value”, typically a relatively short hexadecimal (“hex”) value (consisting of digits and the characters from A to F) out of any given payload data, e.g. file. Already the smallest changes in the payload data result in a totally different hash value. This property can be utilized in a wide range of applications from cryptography to file verification.
In media workflows hashing algorithms are used to identify changes in a file without having the original file at hand by creating the hash value of the copy and comparing it to the given hash value of the source. If the hash value of the copy is the same as the hash value of the source, it can be inferred, that the content of the copy is the same as the content of the source.
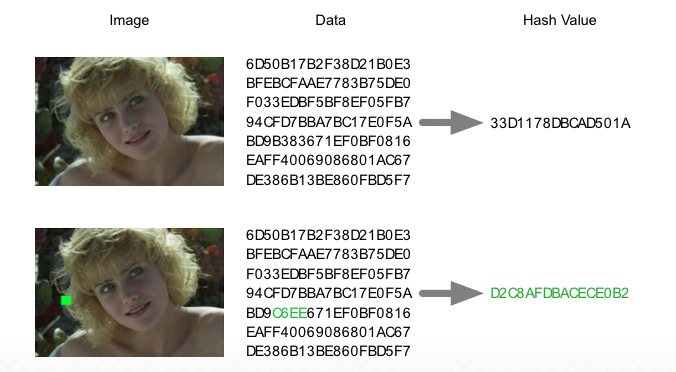
There exist a lot of different algorithms for creating hash values from data. These are the properties of hashing algorithms:
- Computing complexity: More complexity in the hashing algorithms require more computer power to be calculated, decreasing performance.
- Collision probability: It defines the probability that different files have same hash (high probability is bad)
- Detection of modifications: modifications in a file lead to different hash (very important)
xxhash compared to md5 and sha-1
- xxHash
-
- Computing complexity: very low
- Collision probability: low
- Detection of modifications: very good
- MD5 and SHA1
- Computing complexity: high
- Collision probability: very low
- Detection of modifications: very good
Real world numbers
- MD5 is widely used. It comes from an encryption background, but it can also be used to detect transfer errors. Limited to 300MB/sec on recent hardware. MD5 is so complex to calculate, that more than 300 MB/sec is not possible on today’s computers. It checks the entire content of each file and its size.
- SHA1 also comes from an encryption background, but can also be used to detect transfer errors. Limited to 300MB/sec on recent hardware. Checks the entire content of each file and its size.
- xxHash is not a cryptographic algorithm. For detecting transfer errors is as safe as MD5. However, it is incredibly fast. In theory it can generate check sums at several GB/sec. Checks the entire content of each file and its size. Specially useful with high speed data transfer hardware. Only faster than MD5 or SHA1 if the transfer speed of all the sources and destinations is higher than 350MB/s. Caution! Below 300 MB/sec xxhash can be a bit slower than MD5/SHA-1, but beyond it’s much faster, because md5 can’t get faster and xxhash goes up to a few GB/sec.
- xxHash64 BE (Big Endian): generally the same as the xxHash algorithm. However, it outputs a hash string in hexadecimal values, which makes it more compatible with some post production workflows. It is potentially faster on very large data transfer rate setups. This hashing algorithm is compatible with Google’s xxhash implementation. Endianness information: https://en.wikipedia.org/wiki/Endianness
- xxHash64 LE/legacy (Little Endian): generally the same as the algorithm xxHash64 BE (Big Endian). However, it outputs a hash string in a Little Endian format. Used in legacy workflows. Endianness information: https://en.wikipedia.org/wiki/Endianness

Hashing algorithms in Silverstack
The different verification methods (hashing algorithms) are selectable from the Offload and Backup wizards:
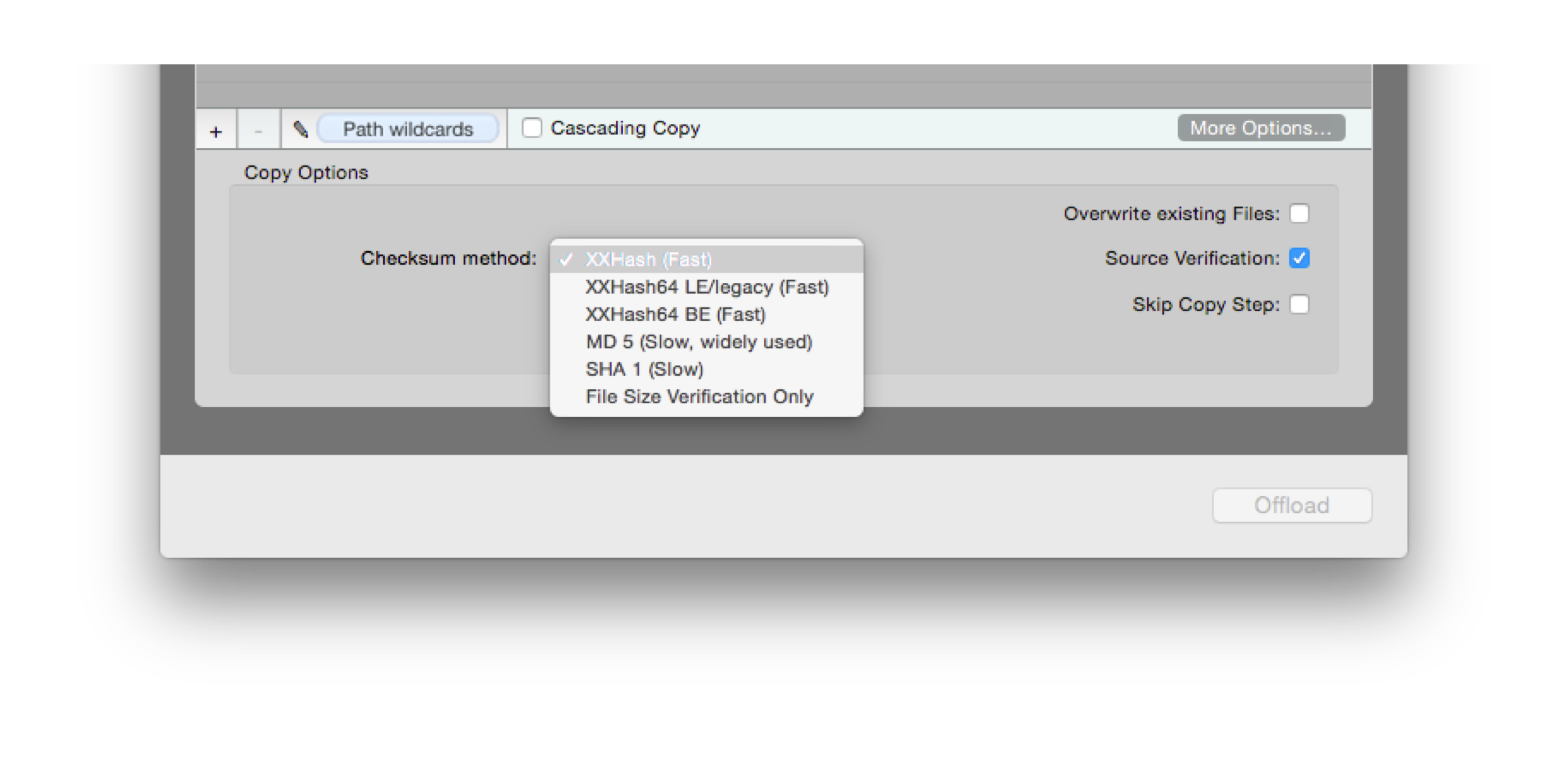
figure 3: checksum methods
Source verification
As shown in figure 3, by default Silverstack does a source verification with each copy, meaning that the files are read from the source again after being copied. This is the most secure way to ensure data integrity because it’s possible to detect read errors too. However it is possible to speed up the copy and verification process by disabling this option. In that case the files are only read form the source once when making the actual copy. If the source is extremely slow, it could make sense to disable it, as it can slow down the verification process. Only then it should be skipped, as it doesn’t affect the process if the source is as fast as the destination.
MD5 files generation
There is the option to create MD5 files in addition to the MHL ones. This will give compatibility for any post production process asking for this kind of files. The MD5 legacy files are only created when the MD5 verification method is used.
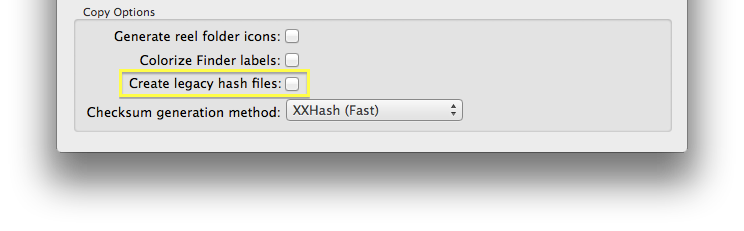
figure 4: create legacy check sum files
Sources:
https://code.google.com/p/xxhash/
Related articles:
How does Silverstack’s copy process work?